A Question of Ground Truth in an AI World
- Recap
- Limitations of Predict-to-Decide
- Satya-Rta-Dharma versus ML Data Model
- Limitations of choosing Language as Ground Truth
- Does AI have real power?
- Limitations of Position-to-Decide
- References
Recap
In post #5, we identify a key trait of decisions (integrality) that withstand the passage of time. The actual opposite of fragility is integrality, not antifragility. Policy must incorporate the interconnectedness of Satya, Rta, and Dharma, in that sequence (shown as nested circles), for integral decision-making. A recent trend of favoring Rta over Satya carries dire implications. We’ll examine why it’s essential to get this priority right in the current AI environment. The question of pramana, crucial for any Indic/Dharmic approach to discovery, is our focus. What is the pramana for a good decision policy? The whole series leads to this question, and we’ll examine it in this post and the following one.
Note: All emphases within quotes in bold belong to this author.
Limitations of Predict-to-Decide
AI systems utilize a predict-to-decide approach, relying on ML models like artificial neural networks to make predictions. These predictions are quantified as probabilities of different outcomes. The decision-making algorithm uses these probabilities to identify a best likely action. This approach is the cutting-edge technology for automated, algorithmic decision making. To illustrate, a self-driving car’s ML system processes images, determining an 90% likelihood of an upcoming stop sign, and then applies the brakes. There is no guarantee of accuracy from the system. It’s possible the car is braking for a guy on the sidewalk, who’s wearing a shirt with a logo similar to a stop sign.
Generative AI (GenAI) has captivated the public and many believe it’s a step towards Artificial General Intelligence (AGI) and sentient machines. Incorporate ‘Agentic workflows‘ and you get autonomous virtual agents that facilitate rapid and automated decision making at scale. Can such GenAI systems, with their ML capability of working with very large contexts, make ‘superhuman’ decisions for us?
The Indic approach to this question involves seeking pramana, the method for obtaining valid knowledge. The reader is referred to several other articles in ICP that discuss pramana. The pramana for a good machine learning prediction system is how well it performs compared to the ground truth chosen for the task [1]:
“In machine learning, the term ground truth refers to the reality you want to model with your supervised machine learning algorithm. Ground truth is also known as the target for training or validating the model with a labeled dataset. During inference, a classification model predicts a label, which can be compared with the ground truth label, if it is available.”
This pramana, while available for prediction, is provisional and not absolute, contingent on the availability of ground truth data that meets technical assumptions like ‘IID’ and ‘stationarity’. The pramana for the subsequent decision is conditional on the accuracy of the ML prediction, among other factors. This differs from the pramana (e.g. Pratyaksha, Anumana) accepted in Indic knowledge systems such as Ganita. There’s no pramana to validate real-world performance of predict-to-decide because ML is designed to identify statistical correlations, not causal relationships.

Good ML models possess the property of ‘prapakatva’. It strives to provide a ‘best-fit’ response aligned with the chosen ground truth, without asserting its truthfulness. Similar to how high-cost errors make ML problematic, ML shines in tasks where the potential gain from being right outweighs the cost of mistakes. As one illustration, the discovery of new materials has been revolutionized by the combination of machine learning and domain knowledge.
The choice or availability of a good quality ‘ground truth’ makes an enormous difference to the system performance. Let’s analyze three examples:
Example 1: We use the forecast for tomorrow’s highest temperature to decide whether to hold an outdoor event. The factual daily temperature is a measurable ground truth for this prediction; it is pretty solid, cyclical, and a part of Rta.
Example 2: We are predicting car license plate numbers using image data from the CCTV cameras. The ground truth is the set of license plates that could be bent, scratched, faded, obscured from view, etc. in very different ways, The association with reality is weaker compared to the previous example and the user cannot be sure of the predicted numbers.
Example 3: A parent uses a Large language model (LLM) bot to decide what medicine to give to their child who appears to be sick. The LLM bot’s training data may have varying degrees of truthfulness and connection to reality. A weaker proxy of Rta serves as the ground truth here. The LLM input and output may contain stuff that is made up and does not even exist.
These three examples’ predictions relate to escalating levels of uncertainty: truth, semantic, and ontological uncertainty [8]. The reliability of decisions based on these predictions decreases. To add to this challenge, a crooked technician or a broken thermometer could produce fabricated or bad data, and stuff that look like license plates can mess things up in the second example. When there is no pramana for even the ground truth, poor decisions are to be expected.
Satya-Rta-Dharma versus ML Data Model
“If Satya is the law and Rta is the execution of the law, what then is Dharma?—upholding of the Law… Where Dharma is the letter, Rta is the spirit. Where Rta is the letter, Satya is the Spirit. It is the spirit of the law (Justice) that gives law its legitimacy. Law without Justice is Tyranny… as is Rta without Satya.. Rta is not merely the physical and biological cycles but also, critically, harmony and natural justice.” [4].
The real-world robustness of each of the three ‘predict-to-decide’ scenarios discussed earlier hinges on the alignment of the corresponding ground truth with Rta. Note that a ground truth is available to predictive AI models for evaluating predictions, but not for decisions. For example, the Modi government’s 2016 demonetization decision took India along a certain trajectory with cascading future effects, including the hardships experienced by the people. The ground reality before-and-after offer a side-by-side comparison and a narrative to criticize the decision. However, we do not have the factual outcome of deciding not to demonetize; we only have a counterfactual (’what if?’) estimate of the resultant reality, which shows major positive impacts of demonetizing versus not. Interested readers are referred to the counterfactual analysis of ‘King Hemu in the tent’ in the previous post.
A core unresolved problem with using AI in critical decision-making applications is its unreliability and inability to capture cascading consequences (see part-1). Researchers at Princeton University, in their well-received book ‘AI Snake Oil’ [13], point out that: “AI can make good predictions if nothing else changes … predictive AI does not account for the impact of its own decisions.” [12] The authors emphasize: “Accepting the inherent randomness and uncertainty in many of these outcomes could lead to better decisions ...” The authors may well be expressing a message of the Bhagavad Gita. The ability to be at peace with chaos and balance it with order is intrinsic to Indic decision-making [10].
 The fundamental strength and limitation of current AI/ML models is its data model. It is a strength because it does not rely on theories and stylized math models, and lets the data do all the talking. However, the most frequently occurring historical patterns dominate the data, which are also riddled with error, bias, and adharma. Such a ground truth is always incomplete, as it cannot tractably overcome the curse of dimensionality (see part-4). We must manage data issues before tackling the ML algorithm and its decisions. The ML prediction algorithm finds correlations in this data, including spurious and meaningful connections. These correlations could indicate the cycles of Rta, and on occasion, patterns of adharma. It lacks the ability to discern the difference.
The fundamental strength and limitation of current AI/ML models is its data model. It is a strength because it does not rely on theories and stylized math models, and lets the data do all the talking. However, the most frequently occurring historical patterns dominate the data, which are also riddled with error, bias, and adharma. Such a ground truth is always incomplete, as it cannot tractably overcome the curse of dimensionality (see part-4). We must manage data issues before tackling the ML algorithm and its decisions. The ML prediction algorithm finds correlations in this data, including spurious and meaningful connections. These correlations could indicate the cycles of Rta, and on occasion, patterns of adharma. It lacks the ability to discern the difference.
When we outsource our decision-making to AI, we are also exchanging the ground truth of dharma for the values and worldview built into its training data and ML models by its developers. As quoted in part-2, the most consequent truths about this world lie in its nuances, subtleties, and in the inexpressible. What we get with ML is the opposite: plentiful, superficial data.
A major area of AI research focuses on the so-called ‘alignment problem,’ which examines how to align AI-generated decisions with ethics and human values. Good quality curated datasets may embed a high degree of the transactional truth, but rarely do datasets represent Rta accurately and without bias (Rta includes harmony and natural justice).
While the state-of-the-art LLM based systems can give us efficiency and speed, an inherent limitation remains: language by itself is not truth and lacks integrality. This becomes the natural limit for what LLMs can hope to achieve and erudite fraudacharyas who emphasize the letter and forget the intent and spirit must understand these limitations, especially.
Limitations of choosing Language as Ground Truth
Sri Nisargadatta Maharaj [3]:
“Words can bring you only unto their own limit; to go beyond, you must abandon them.”
1. LLMs are restricted in scope & capability to the Vyavaharika/transactional world
Used carefully, LLMs can still be valuable in the transactional world, but we must be aware of their limits. Swami Sarvapriyananda, in the section on ‘where can we use language’, discusses the commentary of Adi Shankaracharya on the Upanishads, which points out the fundamental limitation of language [2];
Swamiji explains that there are five areas where languages (that includes symbols) work, and in the state of turiyam, none of these five apply. This pours cold water over the belief that advanced LLM architectures, or hybrids that incorporate ‘symbolic AI’ and its structured rules using symbolic language, will lead us to AGI and machine sentience. This belief is consistent with a western worldview of consciousness emerging from the neural activity and that it is computable. However, such an ‘AI consciousness’ relying on language cannot be turiyam.
2. Shabda Jaalam, the language maze
The wisdom of ancient Bharata figured out that language is useful but can only take you only so far and no further. For brevity, it suffices to quote a dharmic text (Vivekachudamani, shlokam.org) and a related discussion by Rajiv Malhotra in ‘Indra’s Net’ [9].

“Post-modern deconstruction, however, promises only textual liberation; since it does not help one go beyond text, one becomes trapped indefinitely in the labyrinth of logo-centrism. The post-modernist remains inscribed within an endless web of concepts because he still identifies with language… Shastras (spiritual texts) provide useful pointers to the spiritual seeker, but must eventually be transcended lest they become a trap in their own way.”
3. Presence of Non-translatables
Accurate and meaningful mechanical translation of key cultural and civilizational concepts is not possible because of the presence of many non-translatables [10]. To comprehend non-translatables such as Shraddha and Sadhana require one to go beyond text and have an immersive dharmic experience.
4. The fact is always non-verbal
For brevity, it is enough to cite this explanation of Sri Nisargadatta Maharaj (thanks to @shaliniscribe). The implication for the capability of language models is huge.

Emily Bender [14] coined the term ‘stochastic parrots’ to describe the performance of LLMs: “an LM is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot”.

A 2024 study [17] found that LLMs struggle with language comprehension tasks. According to the report, the AI lacks sensitivity to underlying meanings. The Bharatiya understanding of language came long before the modern finding that language is a useful tool for communication rather than thought [6].
The story of Nigel Richards, the man from New Zealand who memorized every French word in the French scrabble dictionary and won the French Scrabble Championship without speaking any French
[read more: https://t.co/lP9Ybrmxy1] pic.twitter.com/3XpccxdMWC
— Massimo (@Rainmaker1973) November 23, 2023
What about the Vedas?
Vaidikas consider Vedas to be shabda pramana, encoding true knowledge. Bharatiyas have (in both letter and spirit) faithfully preserved and transmitted the Vedas for thousands of years through embodied learning. It The oral tradition of Vedic transmission works better that the modern “write and forget” as it involves a very high frequency of checks of quality, intonation, understanding along with error-detection and correction built into the process. The vibrations of the Sanskrit chants elevate our consciousness and enable a deeper realization [10]. Today, digitized versions of Vedic texts are available online to read and memorize, but offer only a disembodied learning approach. These written or digitized versions freeze the texts into unidimensional snapshots. Mastering the text alone is akin to becoming a theoretical martial artist.
Consider this: a sufficiently powerful LLM and/or Symbolic AI system can effectively replace the theological knowledge and religious advice given by the topmost cleric of a global organized religion. Training the largest LLM on the entire Vedic corpus of text and all their commentaries over the millennia will not produce an authentic “AI” Rishi or Yogi. Their respective knowledge arises from two different ground truths (more on this in the next part).
Does AI have real power?
A knowledge system’s ground truth sets the limits for its power.
The process of discovery and progress in current AI/ML (from 1950s to present) is not the same as that of science, the recent Nobel Prize notwithstanding. Well-designed science lab experiments, based on direct observation of reality, produce results that generalize and replicate well in the real world. A successful AI/ML experiment using carefully curated historical training data does not point to real success in the same way. AI/ML equations represent complex ‘curve fitting’ conditions and not deep causal insights into Rta.
AI/ML is also not the same as formal mathematics with its ground truth of deductive logic. ML progresses not by theorem proving but by beating prior benchmarks and getting on top of a ‘leaderboard’. Thus, it can produce spectacular successes and dramatic failures. Despite the hype, its chosen ground truth limits the ML’s predictive capability. Its results are not readily transferrable across domains (and hence the quest for AGI). AI needs a human expert to check its work and fix any mistakes. However, good-quality AI can function well as a decision support system.
“In any ranking of near-term worries about AI, superintelligence should be far down the list. In fact, the opposite of superintelligence is the real problem.”–Melanie Mitchell [7].
“We should be afraid. Not of intelligent machines. But of machines making decisions that they do not have the intelligence to make … Machine stupidity creates a tail risk. Machines can make many many good decisions and then one day fail spectacularly on a tail event that did not appear in their training data.”–Sendhil Mullainathan, quoted in [7].
Is current AI really powerful? No, and yes. Top-down authors who think of AI as science or formal math have gotten it wrong in attributing its power to its ‘superhuman performance’. This excessive AI hype does a disservice to many researchers and engineers in the trenches. AI is super-mechanically capable but engineers struggle to build applications with AI modules due to their inconsistent and unpredictable output, unlike conventional software components. It’s time to analyze some claims made in books.
Claim: AI beats humans on image recognition.
No. The marketing and the dramatic license of media reports have misled these authors who claim this as a fact.
“.. companies made it clear they were talking about accuracy specifically on ImageNet, the media were not so careful, giving way to sensational headlines such as, ‘Computers Now Better than Humans at Recognising and Sorting Images’ and ‘Microsoft Has Developed a Computer System That Can Identify Objects Better than Humans.’”– [7].
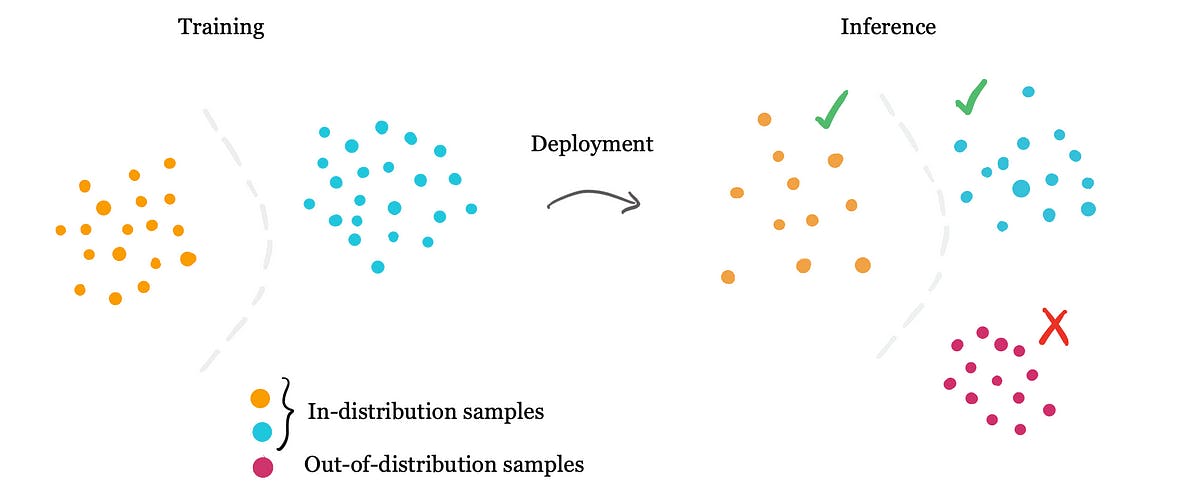
The ImageNet dataset serves as a limited ground truth, and researchers report out-of-sample accuracy for this specific dataset. This well-cited 2019 paper highlights a persistent problem in image recognition: AI struggles to reliably generalize from limited training data. Also see this 2023 NeurIPS paper. Consider an ML model trained using digital images of cows and horses. This ML model would find it hard to classify anything outside this ground truth (e.g., other animals). In fact, the accuracy would decrease for classifying images of cow and horse breeds that differ significantly (‘out of distribution‘) from those used in the training data.
Claim: AI can learn on their own.
No. Training good AI models requires curated datasets and a lot of expert human effort and feedback. Indeed, permitting these machine learning models to learn indiscriminately from all data sources can cause ‘model collapse‘ [15]. Also this. Generative AI usage has already polluted some critical language data sources that were organic. The current systems are fragile, and even a small percentage of poor synthetic data can degrade their performance.
“If deep-learning systems, so successful at computer vision and other tasks, can easily be fooled by manipulations to which humans are not susceptible, how can we say that these networks, ‘learn like human’ or, ‘equal or surpass humans’ in their abilities?” –[7].
Claim: AI learn similar to the way humans learn.
No. This is a disappointing claim by authors. It’s common knowledge in the AI research space that ML systems learn inefficiently, unlike humans who can generalize from a few examples. A misuse of nama rupa causes this misunderstanding by attributing to “AI” all kinds of human qualities and terminology such as “learning”, “neural”, “solver”, etc., which the developers wished these machines would possess. Drew McDermott [16] coined the term “wishful mnemonic” in 1976 for this naming trick:
“People give computational variables or procedures the names of natural intelligence phenomena, without much regard to any real similarity between the procedure and the natural phenomena … In fact there is often very little similarity of the algorithm or the functions to any known realities of biological neurons, except in a very gross sense … the temptation of wishful mnemonics: words that wishfully call a computational construct by the name of human characteristic, while the real similarity isn’t established scientifically.” – RE Smith [8].
“Everything wrong about our perception of machine learning and AI is due to excessive anthropomorphism — which the field actively promotes.” – François Chollet, the creator of Keras.
Wishful mnemonics cannot overcome the limitation inherent in the chosen ground truth. Although the technical discussion has been extensive, it’s crucial to address the more outrageous claims about AI by asking for pramana.
What is the source of AI’s power? The media focuses more on the wishful ‘intelligence’ part, but its long-term power comes from the artificial part, which we argue in the second half of this post, is rooted in the western worldview.
GenAI’s ability to simulate reasoning and understanding is growing by the day, even though it possesses neither common sense nor understanding. As M. Mitchell says in her book [7]: “[Douglas] Hofstadter’s terror was in response to something entirely different. It was not about AI becoming too smart, too invasive, too malicious, or even too useful. Instead, he was terrified that intelligence, creativity, emotions, and maybe even consciousness itself would be too easy to produce—that what he valued most in humanity would end up being nothing more than a ‘bag of tricks,’ that a superficial set of brute-force algorithms could explain the human spirit.”
This issue is a major concern to dharmic practitioners and something that our traditional Matthas should look into. The challenge is this:
AI doesn’t need to become sentient; all it needs to do is appear to be ‘conscious’ within the scope of its ground truth. This will be enough for many to forget about the lack of pramana and myopically reject the dharma traditions of Vaidika, Bauddha, and Jaina. The practitioners of these diverse traditions accept the truth-claim of an ultimate reality (an integral unity [10]) as a core principle. As AI/ML systems continue to excite and terrify audiences, it becomes easier to accept this seemingly omnipotent AI as a substitute ground truth.
The western worldview that consciousness is an emergent property of neural activity contradicts the Mahavakyas of the Upanishads. One is free to adopt a Charvaka lifestyle, let go of Purusharthas and handoff critical decisions to omniscient AI apps. This outsourcing mindset encourages opportunists to weaponize these error-prone systems to rake in the profits and let the users deal with the consequences of decisions gone wrong, which leads to adharma at scale. There is an enormous price to be paid for ignoring the fundamental principle of Satya-Rta-Dharma and relying instead on AI/ML systems for decision-making.
“the exclusion of wisdom from economics, science. and technology was something which we could perhaps get away with for a little while. as long as we were relatively unsuccessful; but now that we have become very successful, the problem of spiritual and moral truth moves into the central position.”– Ernst Schumacher in ‘Small is Beautiful’ [11].
“The transactional truth is naturally beneath Rta. But the Absolute truth is naturally above it, and that is Satyam-param” [4]: If this were not true and Rta were indeed ahead of Satya, then the spiritual and moral problem of accepting the AI paradigm as truth is a non-issue. Technology can replace our Pujaris, Acharyas, Gurus, and Matthas: an AI/AGI system whose ground truth we accept as an adequate representation of Rta. It is amusing to hear some social media stars of Hindutva extol Sanathana (eternal) Dharma and, in the same breath, also position Rta, something that is ultimately transient, ahead of the eternal Satya. Jagat Satyam Brahma Mithya?
Limitations of Position-to-Decide
Before moving on, let’s briefly review an alternative approach to decision making that we’ve discussed previously. Recognizing the limitations of accurately calculating the probabilities of rare and high consequential future events, another school of thought prefers the alternative of positioning (aka optionality) to be antifragile to such random shocks. A black swan, popularized by Prof. Nassim Taleb, is an unexpected and highly consequential event that comes from outside our ontological understanding, like an ‘out of syllabus’ question in our final exam. Position-to-decide focuses on ‘survival first’ without relying on probabilities.

Here’s an example to think about. Predict-to-decide may recommend carrying an umbrella if the chance of rain is over 50%. The position-to-decide person carries an umbrella always. In vivo or embodied decision-making [8] by human beings can include the elements of subjective prediction (“I fancy my chances”) and positioning (“I have a Plan B just in case”). Position-to-decide eliminates the dependency on an explicit ground truth about the weather at the cost of carrying an umbrella around. The position-to-decide strategy is both strengthened and weakened by the absence of a ground truth.
The latter half of this post contrasts the ground truths of the two aforementioned approaches with the integral decision-making approach embedded within Indic/Bharatiya traditions.
References:
- Domino Data Lab. Data Science Dictionary: What is Ground Truth in Machine Learning?
- Swami Sarvapriyananda. “Who Am I?” according to Mandukya Upanishad.” (Part 1). IIT Kanpur. 2014.
- Nisargadatta Maharaj. I am That: Talks with Sri Nisargadatta Maharaj. Edited by Sudhakar S. Dikshit. 1981.
- Satya, then Rta, then Dharma. Indic Civilizational Portal. 2016.
- Vivekachudamani, Verse 60. Shlokam.org.
- Evelina Fedorenko, et al. Nature, Vol. 630. Language is primarily a tool for communication rather than thought. 2024.
- Melanie Mitchell. Artificial Intelligence: A Guide for Thinking Humans. Farrar, Straus and Giroux. 2019.
- Robert Elliot Smith. Idealizations of Uncertainty, and Lessons from Artificial Intelligence — Economics E-Journal. 2015.
- Rajiv Malhotra. Indra’s Net: Defending Hinduism’s Philosophical Unity. HarperCollins. 2014.
- Rajiv Malhotra. Being Different: An Indian Challenge to Western Universalism. Harper Collins. 2011.
- Ernst Friedrich Schumacher. Small Is Beautiful: Economics as if People Mattered. Thesis, 1977.
- Angelina Wang, et al. Against Predictive Optimization: On the Legitimacy of Decision-Making Algorithms that Optimize Predictive Accuracy. Proceedings, ACM Conference on Fairness, Accountability, and Transparency. 2023.
- Arvind Narayanan and Sayash Kapoor. AI Snake Oil: What Artificial Intelligence Can Do, What It Can’t, and How to Tell the Difference. Princeton University Press. 2024.
- Emily M. Bender, et al. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Proceedings, ACM Conference on Fairness, Accountability, and Transparency. 2021.
- Elvis Dohmatob, et al. Strong Model Collapse. https://arxiv.org/abs/2410.04840. 2024.
- Drew McDermott. Artificial Intelligence Meets Natural Stupidity. SIGART Newsletter, 57. 1976.
- Vittoria Dentella, et al. Testing AI on language comprehension tasks reveals insensitivity to underlying meaning. Sci Rep 14. 2024.


